7. SQL基础(二)
在“SQL基础(一)”部分我们介绍了一些SQL的基础知识,包括SQL查询语句的基础结构语法说明、日期时间、分组聚合、子查询和关联查询等内容。接下来我们继续介绍一些常用的SQL基础知识点。
常用日期函数和日期时间间隔使用
区块链的数据都按交易发生的时间先后顺序被记录保存,日常数据分析中经常需要对一段时间范围内对数据进行统计。上一部分介绍过的date_trunc()函数用于按指定的间隔(天、周、小时等)截断日期值。除此之外还有一些常用的函数和常见用法。
1. Now()和Current_Date()函数
函数now()用于获取当前系统的日期和时间值。需要注意,其内部保存的是包括了时分秒值的,但是Dune的查询编辑器默认只显示到“时:分“。当我们要将日期字段跟价格表prices.usd中的minute字段进行关联时,必须先按分钟进行截取。否则可能关联不到正确的价格记录。
函数current_date()用于获取当前日期(不含时分秒部分)。当我们需要按日期、时间筛选数据时,常常需要结合使用它们其中之一,再结合相关日期时间函数来换算出需要的准确日期或者时间。函数current_date()相当于date_trunc('day', now()),即对now()函数的值按“天”进行截取。还可以省略current_date()的括号,直接写成current_date形式。
select now() -- 当前系统日期和时间
,current_date() -- 当前系统日期
,current_date -- 可以省略括号
,date_trunc('day', now()) -- 与current_date相同
2. DateAdd()、Date_Add()、Date_Sub()和DateDiff()函数
函数dateadd(unit, value, expr)在一个日期表达式上添加一个的日期时间单位。这里的“日期时间单位”使用常量表示,常用的有HOUR、DAY、WEEK、MONTH等。其中的value值可以为负数,表示从后面的表达式减去对应的日期时间单位。也正是因为可以用负数表示减去一个日期时间间隔,所以不需要也确实没有datesub()函数。
函数date_add(startDate, numDays)在一个日期表达式上加上或者减去指定的天数,返回另外一个日期。参数numDays为正数表示返回startDate之后指定天数的日期,为负表示返回之前指定天数的日期。函数date_sub(startDate, numDays)作用类似,但表示的意思正好相反,即负数表示返回之后的日期,正数表示之前的日期。
函数datediff(endDate, startDate)返回两个日期表达式之间间隔的天数。如果endDate在startDate之后,返回正值,在之前则返回负值。
SQL示例如下:
select date_add('MONTH', 2, current_date) -- 当前日期加2个月后的日期
,date_add('HOUR', 12, now()) -- 当前日期时间加12小时
,date_add('DAY', -2, current_date) -- 当前日期减去2天
,date_add('DAY', 2, current_date) -- 当前日期加上2天
,date_add('DAY', -5, current_date) -- 当前日期加上-5天,相当于减去5天
,date_diff('DAY', date('2022-11-22'), date('2022-11-25')) -- 结束日期早于开始日期,返回负值
,date_diff('DAY', date('2022-11-25'), date('2022-11-22')) -- 结束日期晚于开始日期,返回正值
3. INTERVAL 类型
Interval是一种数据类型,以指定的日期时间单位表示某个时间间隔。以Interval 表示的时间间隔使用起来非常便利,避免被前面的几个名称相似、作用也类似的日期函数困扰。
select now() - interval '2' hour -- 2个小时之前
,current_date - interval '7' day -- 7天之前
,now() + interval '1' month -- 一个月之后的当前时刻
更多日期时间相关函数的说明,请参考日期、时间函数和运算符
条件表达式Case、If
当我们需要应用条件逻辑的时候,可以应用case语句。CASE语句的常用语法格式为CASE {WHEN cond1 THEN res1} [...] [ELSE def] END,它可以用多个不同的条件评估一个表达式,并返回第一个评估结果为真值(True)的条件后面的值,如果全部条件都不满足,则返回else后面的值。其中的else部分还可以省略,此时返回NULL。
我们在“Lens实践案例:创作者个人资料域名分析”部分就多次用到了CASE语句。其中部分代码摘录如下:
-- ...省略部分代码...
profiles_summary as (
select (
case
when length(short_name) >= 20 then 20 -- 域名长度大于20时,视为20对待
else length(short_name) -- 域名长度小于20,直接使用其长度值
end) as name_length, -- 将case语句评估返回的结果命名为一个新的字段
handle_type,
count(*) as name_count
from profile_created
group by 1, 2
),
profiles_total as (
select count(*) as total_profile_count,
sum(case
when handle_type = 'Pure Digits' then 1 -- 类型值等于给定值,返回1
else 0 -- 类型值不等于给定值,返回 0
end
) as pure_digit_profile_count,
sum(case
when handle_type = 'Pure Letters' then 1 -- 类型值等于给定值,返回1
else 0 -- 类型值不等于给定值,返回 0
end
) as pure_letter_profile_count
from profile_created
)
-- ...省略部分代码...
可以看到,通过CASE语句,我们可以根据实际的需要对数据进行灵活的转换,方便后续的统计汇总。
上述示例查询的相关链接:
函数if(cond, expr1, expr2) 的作用时根据条件值评估的真假,返回两个表达式中的其中一个值。如果条件评估结果为真值,则返回第一个表达式,如果评估为假值,则返回第二个表达式。
select if(1 < 2, 'a', 'b') -- 条件评估结果为真,返回第一个表达式
,if('a' = 'A', 'case-insensitive', 'case-sensitive') -- 字符串值区分大小写
字符串处理的常用函数
- Substring() 函数
当有时我们因为某些特殊的原因不得不使用原始数据表transactions或logs并解析其中的data数据时,需要先从其中提取部分字符串,然后进行针对性的转换处理,此时就需要使用Substring函数。Substring函数的语法格式为substring(expr, pos [, len])或者substring(expr FROM pos [FOR len] ] ),表示在表达式expr中,从位置pos开始,截取len个字符并返回。如果省略参数len,则一直截取到字符串末尾。
- Concat() 函数和 || 操作符
函数concat(expr1, expr2 [, ...] )将多个表达式串接到一起,常用来链接字符串。操作符||的功能和Concat函数相同。
select concat('a', ' ', 'b', ' c') -- 连接多个字符串
, 'a' || ' ' || 'b' || ' c' -- 与concat()功能相同
- Right() 函数
函数
right(str, len)从字符串str中返回右边开始计数的len个字符。如前所述,在logs这样的原始数据表里数据是按64个字符一组连接到一起后放入data里面的,对于合约地址或用户地址,其长度是40个字符,在保存时就会在左边填充0来补足64位长度。解析提取地址的时候,我们就需要提取右边的40个字符,再加上0x前缀将其还原为正确的地址格式。
注意,在Dune SQL中,直接使用right()函数可能返回语法错误,可以将函数名放到双引号中来解决,即使用"right"()。由于这种方式显得比较繁琐,我们可以使用substring函数的负数开始位置参数来表示从字符串右边开始计数确定截取的开始位置。
下面是一个使用上述函数的一个综合例子,这个例子从logs表解析跨链到Arbitrum的记录,综合使用了几个方式:
select date_trunc('day', block_time) as block_date, --截取日期
concat('0x', "right"(substring(cast(data as varchar), 3 + 64 * 2, 64), 40)) as address, -- 提取data中的第3部分转换为用户地址,从第3个字符开始,每64位为一组
concat('0x', "right"(substring(cast(data as varchar), 3 + 64 * 3, 64), 40)) as token, -- 提取data中的第4部分转换为用户地址
concat('0x', substring(substring(cast(data as varchar), 3 + 64 * 3, 64), -40, 40)) as same_token, -- 提取data中的第4部分转换为用户地址
substring(cast(data as varchar), 3 + 64 * 4, 64) as hex_amount, -- 提取data中的第5部分
bytearray_to_uint256(bytearray_substring(data, 1 + 32 * 4, 32)) as amount, -- 提取data中的第5部分,转换为10进制数值
tx_hash
from ethereum.logs
where contract_address = 0x5427fefa711eff984124bfbb1ab6fbf5e3da1820 -- Celer Network: cBridge V2
and topic0 = 0x89d8051e597ab4178a863a5190407b98abfeff406aa8db90c59af76612e58f01 -- Send
and substring(cast(data as varchar), 3 + 64 * 5, 64) = '000000000000000000000000000000000000000000000000000000000000a4b1' -- 42161,直接判断16进制值
and substring(cast(data as varchar), 3 + 64 * 3, 64) = '000000000000000000000000c02aaa39b223fe8d0a0e5c4f27ead9083c756cc2' -- WETH,直接判断16进制值
and block_time >= now() - interval '30' day
limit 10
上述示例查询的相关链接:
窗口函数
多行数据的组合成为窗口(Window)。对窗口中的一组行进行操作并根据该组行计算每一行的返回值的函数叫窗口函数。窗口函数对于处理任务很有用,例如计算移动平均值、计算累积统计量或在给定当前行的相对位置的情况下访问行的值。窗口函数的常用语法格式:
function OVER window_spec
其中,function可以是排名窗口函数、分析窗口函数或者聚合函数。over是固定必须使用的关键字。window_spec部分又有两种可能的变化:partition by partition_feild order by order_field或者order by order_field,分别表示先分区再排序和不分区直接排序。除了把所有行当作同一个分组的情况外,分组函数必须配合 order by来使用。
- LEAD()、 LAG() 函数
Lead()函数从分区内的后续行返回指定表达式的值。其语法为lead(expr [, offset [, default] ] )。Lag()函数从从分区中的前序行返回指定表达式的值。当我们需要将结果集中某一列的值,跟上一行或者下一行的相同列的值进行比较(当然也可以间隔多行取值)时,这两个函数就非常有用。
我们之前的教程中介绍过一个查询,用于统计Uniswap V3 近30天每日新增资金池数量。其SQL为:
with pool_details as (
select date_trunc('day', evt_block_time) as block_date, evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
where evt_block_time >= now() - interval '29' day
)
select block_date, count(pool) as pool_count
from pool_details
group by 1
order by 1
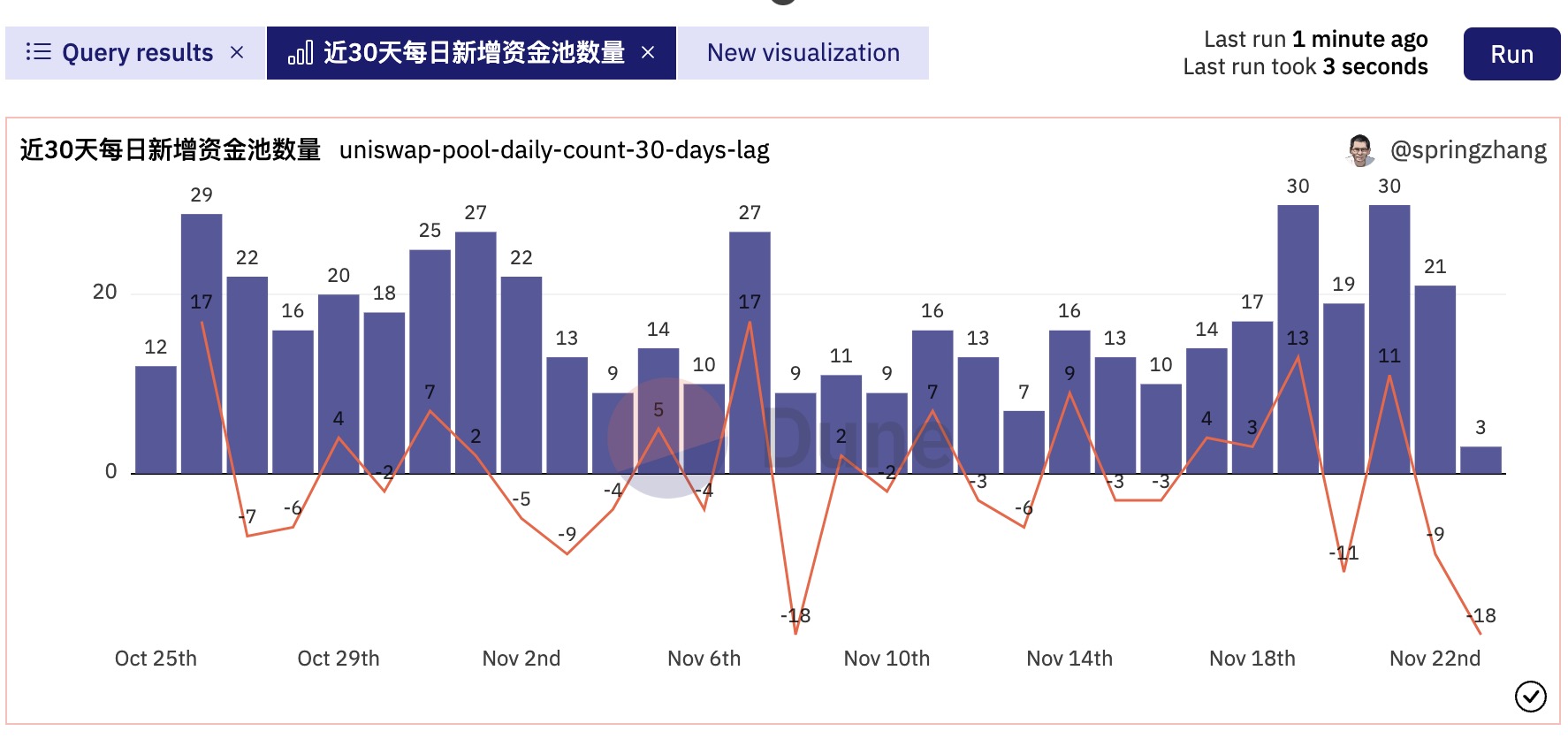
如果我们在目前的条形图基础上还希望添加一条曲线来显示每天新建资金池数量的变化情况,就可以使用Lag()函数来计算出每天相较于前一天的变化值,然后将其可视化。为了保持逻辑清晰,我们增加了一个CTE,修改后的SQL如下:
with pool_details as (
select date_trunc('day', evt_block_time) as block_date, evt_tx_hash, pool
from uniswap_v3_ethereum.Factory_evt_PoolCreated
where evt_block_time >= now() - interval '29' day
),
pool_summary as (
select block_date,
count(pool) as pool_count
from pool_details
group by 1
order by 1
)
select block_date,
pool_count,
lag(pool_count, 1) over (order by block_date) as pool_count_previous, -- 使用Lag()函数获取前一天的值
pool_count - (lag(pool_count, 1) over (order by block_date)) as pool_count_diff -- 相减得到变化值
from pool_summary
order by block_date
将pool_count_diff添加到可视化图表(使用右侧坐标轴,图形类型选择Line),效果如下图:
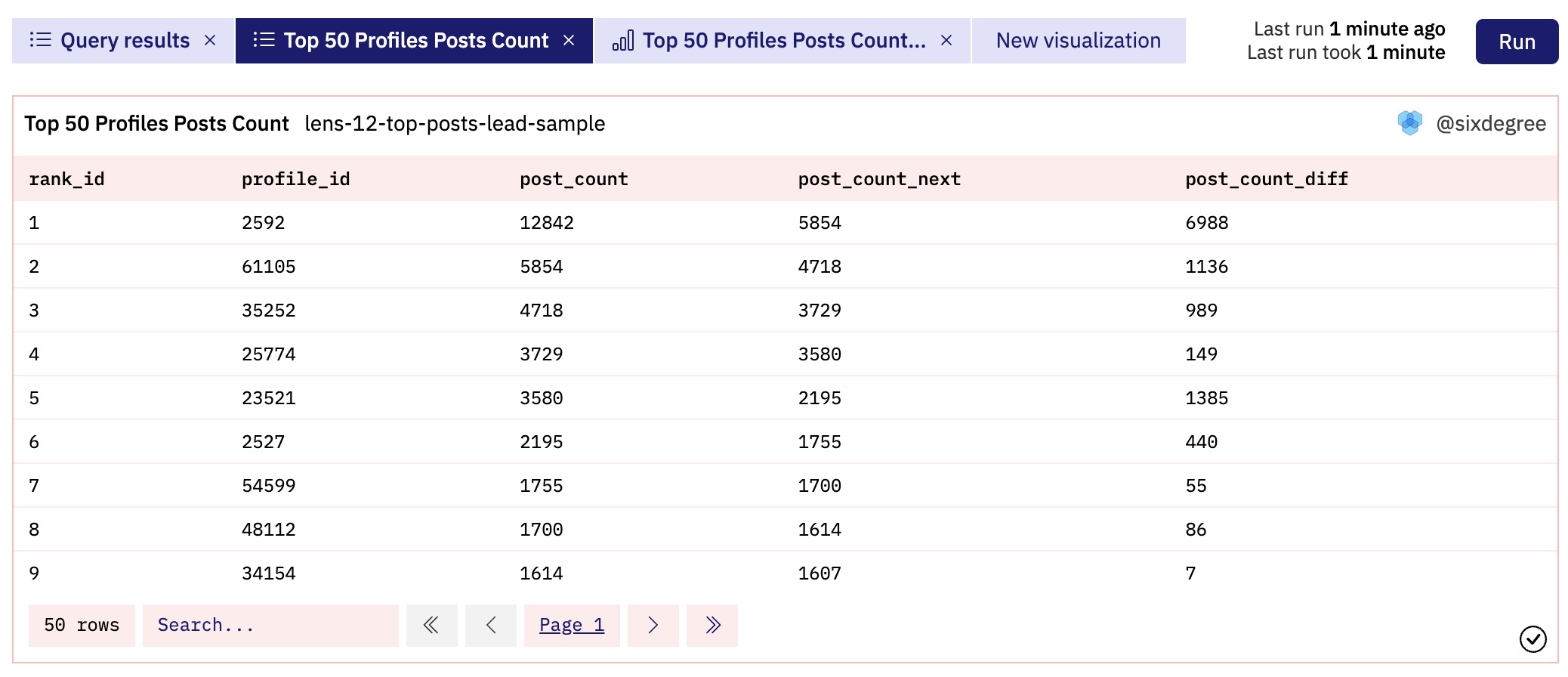
当我们需要向“前”对比不同行的数据时,就可以使用Lead()函数。比如,我们之前在Lens实例中介绍过发布帖子最多的创作者账号查询,我们将其做一些调整,返回发帖最多的50个账号,同时对比这些账号发帖数量的差异(第一名和第二名之差、第二名和第三名之差,等等)。关键部分查询代码如下:
with post_data as (
-- 获取原始发帖详细数据,请参考完整SQL链接
),
top_post_profiles as (
select profile_id,
count(*) as post_count
from post_data
group by 1
order by 2 desc
limit 50
)
select row_number() over (order by post_count desc) as rank_id, -- 生成连续行号,用来表示排名
profile_id,
post_count,
lead(post_count, 1) over (order by post_count desc) as post_count_next, -- 获取下一行的发帖数据
post_count - (lead(post_count, 1) over (order by post_count desc)) as post_count_diff -- 计算当前行和下一行的发帖数量差
from top_post_profiles
order by post_count desc
查询结果如下图所示,其中可以看到有些账号之间的发帖数量差异很小:
完整的SQL参考链接:
- Row_Number() 函数
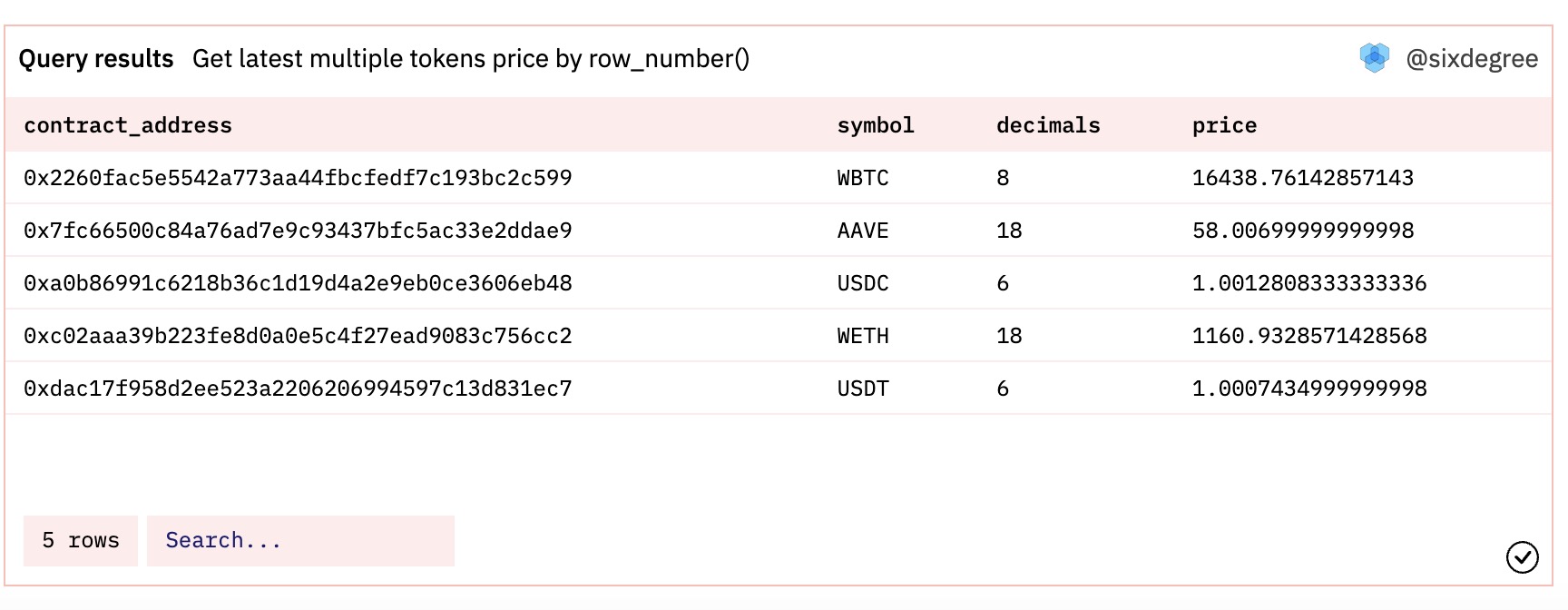
Row_Number() 是一个排名类型的窗口函数,用于按照指定的排序方式生成不同的行号,从1开始连续编号。在上一个例子中,我们已经使用了row_number() over (order by post_count desc) as rank_id来生成行号用来表示排名,这里不再举例。如果结合partition by分区字句,Row_Number()将在每一个分区内部从1开始编号。利用这个特性,我们可以用来实现一些高级筛选。例如,我们有一组Token地址,需要计算并返回他们最近1小时内的平均价格。考虑到Dune的数据会存在一到几分钟的延迟,如果按当前系统日期的“小时”数值筛选,并不一定总是能返回需要的价格数据。相对更安全的方法是扩大取值的时间范围,然后从中筛选出每个Token最近的那条记录。这样即使出现数据有几个小时的延迟的特殊情况,我们的查询仍然可以工作良好。此时我们可以使用Row_Number()函数结合partition by来按分区生成行号再根据行号筛选出需要的数据。
with latest_token_price as (
select date_trunc('hour', minute) as price_date, -- 按小时分组计算
contract_address,
symbol,
decimals,
avg(price) as price -- 计算平均价格
from prices.usd
where contract_address in (
0xdac17f958d2ee523a2206206994597c13d831ec7,
0x2260fac5e5542a773aa44fbcfedf7c193bc2c599,
0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2,
0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48,
0x7fc66500c84a76ad7e9c93437bfc5ac33e2ddae9
)
and minute > now() - interval '1' day -- 取最后一天内的数据,确保即使数据有延迟也工作良好
group by 1, 2, 3, 4
),
latest_token_price_row_num as (
select price_date,
contract_address,
symbol,
decimals,
price,
row_number() over (partition by contract_address order by price_date desc) as row_num -- 按分区单独生成行号
from latest_token_price
)
select contract_address,
symbol,
decimals,
price
from latest_token_price_row_num
where row_num = 1 -- 按行号筛选出每个token最新的平均价格
以上查询结果如下图所示:
完整的SQL参考链接:
窗口函数的更多完整资料:
array_agg()函数
如果你想将查询结果集中每一行数据的某一列合并到一起,可以使用 array_agg()函数。如果希望将多列数据都合并到一起(想象将查询结果导出为CSV的情形),你可以考虑用前面介绍的字符串连接的方式将多列数据合并为一列,然后再应用 array_agg()函数。这里举一个简单的例子:
select array_agg(contract_address) from
(
select contract_address
from ethereum.logs
where block_time >= current_date
limit 10
) t
总结
每一种数据库都有几十个甚至上百个内置的函数,而我们这里介绍的只是其中一小部分常用的函数。如果你想要成为熟练的数据分析师,我们强烈建议阅读并了解这里的每一个内置函数的用法: Trino 函数。
SixdegreeLab介绍
SixdegreeLab(@SixdegreeLab)是专业的链上数据团队,我们的使命是为用户提供准确的链上数据图表、分析以及洞见,并致力于普及链上数据分析。通过建立社区、编写教程等方式,培养链上数据分析师,输出有价值的分析内容,推动社区构建区块链的数据层,为未来广阔的区块链数据应用培养人才。
欢迎访问SixdegreeLab的Dune主页。
因水平所限,不足之处在所难免。如有发现任何错误,敬请指正。